CUDA Learn
- NVIDIA CUDA documentation
- NVIDIA cuda-education
- cuda-samples
- CUDA Programming Course – High-Performance Computing with GPUs
- d_what_are_some_good_resources_to_learn_cuda
- What-are-some-of-the-best-resources-to-learn-CUDA-C
- cuda-training-series
- even-easier-introduction-cuda
- demystifying-gpu-architectures-for-deep-learning
- numba
- GPU-Puzzles
- CUDA 编程入门极简教程
- GPU 编程
- nvvm-ir-spec
NVIDIA CUDA (Compute Unified Device Architecture)
The NVIDIA® CUDA® Toolkit provides a comprehensive development environment for C and C++ developers building GPU-accelerated applications. With the CUDA Toolkit, you can develop, optimize, and deploy your applications on GPU-accelerated embedded systems, desktop workstations, enterprise data centers, cloud-based platforms and HPC supercomputers. The toolkit includes GPU-accelerated libraries, debugging and optimization tools, a C/C++ compiler, and a runtime library to deploy your application.
NVIDIA® CUDA® 工具包为构建 GPU 加速应用程序的 C 和 C++ 开发人员提供了一个全面的开发环境。借助 CUDA 工具包,您可以在 GPU 加速的嵌入式系统、桌面工作站、企业数据中心、基于云的平台和 HPC 超级计算机上开发、优化和部署您的应用程序。该工具包包括 GPU 加速库、调试和优化工具、C/C++ 编译器以及用于部署应用程序的运行时库。
Using built-in capabilities for distributing computations across multi-GPU configurations, scientists and researchers can develop applications that scale from single GPU workstations to cloud installations with thousands of GPUs.
使用内置功能在多 GPU 配置之间分配计算,科学家和研究人员可以开发从单个 GPU 工作站扩展到具有数千个 GPU 的云安装的应用程序。
CUDA C++ Programming Guide v12.6
CUDA 编程模型的关键组成部分 (GPT)
CUDA 编程模型使开发者能够编写代码,充分利用 NVIDIA GPU 的强大并行计算能力。它基于单指令多线程(SIMT)架构,其中多个线程同时执行相同的指令,但处理不同的数据。CUDA 通过分层的线程结构和内存管理系统,高效组织计算任务。
线程层次结构:
- 线程(Thread):执行特定任务的最小执行单元。
- 线程块(Thread Block):线程的集合,线程块中的线程共同执行任务。一个线程块最多包含 1024 个线程(具体取决于 GPU 架构)。
- 网格(Grid):线程块的集合。网格可以是 1D、2D 或 3D,以便更方便地将线程映射到数据上。
通过唯一的索引(如
threadIdx、blockIdx、blockDim和gridDim),每个线程可以访问特定的数据部分。内存层次结构:
- 全局内存(Global Memory):所有线程都可以访问,但访问延迟较高。
- 共享内存(Shared Memory):线程块内的线程共享的一种快速、低延迟的内存。
- 局部内存(Local Memory):每个线程的私有内存,但由于位于全局内存中,访问速度较慢。
- 寄存器(Registers):速度极快,但数量有限,用于存储线程的临时变量。
内核(Kernel):
- CUDA 内核是运行在 GPU 上的函数,使用 C/C++ 语言编写并带有特殊的语法标记。内核从 CPU 发起,并由 GPU 的线程并行执行。
Introduction
The advent of multicore CPUs and manycore GPUs means that mainstream processor chips are now parallel systems.
The challenge is to develop application software that transparently scales its parallelism to leverage the increasing number of processor cores.
The CUDA parallel programming model is designed to overcome this challenge while maintaing a low learning curve for programmers familiar with C.
Its core is three key abstractions:
- a hierarchy of thread groups: 层级线程组
- shared memories: 共享内存
- barrier synchronization: 障碍同步
These abstractions provide fine-grained data parallelism and thread parallelism, nested within coarse-grained data parallelism and task parallelism. They guide the programmer to partition the problem into coarse sub-problems that can be solved independently in parallel by blocks of threads, and each sub-problem into finer pieces that can be solved cooperatively in parallel by all threads within the block.
这些抽象提供了细粒度数据并行性和线程并行性,嵌套在粗粒度数据并行性和任务并行性中。它们引导程序员将问题划分为可以由线程块独立并行解决的粗略子问题,并将每个子问题划分为可以由块内的所有线程并行协作解决的更精细的部分。
This decomposition preserves language expressivity by allowing threads to cooperate when solving each sub-problem, and at the same time enables automatic scalability. Indeed, each block of threads can be scheduled on any of the available multiprocessors within a GPU, in any order, concurrently or sequentially, so that a compiled CUDA program can execute on any number of multiprocessors as illustrated by Figure 3, and only the runtime system needs to know the physical multiprocessor count.
这种分解通过允许线程在解决每个子问题时进行合作来保留语言表达能力,同时实现自动可扩展性。事实上,每个线程块都可以以任何顺序(同时或顺序)调度到 GPU 内的任何可用多处理器上,以便编译后的 CUDA 程序可以在任意数量的多处理器上执行,如图 3 所示,并且仅运行时系统需要知道物理多处理器数量。

A GPU is built around an array of Streaming Multiprocessors (SMs)
GPU 由流式多处理器 (SM) 阵列构建
Programming Model 编程模型
- Kernels: 内核函数
- Thread Hierarachy: 线程层次结构
- Memory Hierarachy: 内存层次结构
- Heteroheneous Programming: 异构编程
- Asynchronous SIMT Programming Model: 异步 SIMT 编程模型
- Compute Capability: 计算能力
Kernels: 内核函数
CUDA C++ extends C++ by allowing the programmer to define C++ functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C++ functions.
CUDA C++ 通过允许程序员定义称为内核的 C++ 函数来扩展 C++,这些函数在调用时由 N 个不同的 CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只能执行一次。
A kernel is defined using the __global__ declaration specifier and the number of CUDA threads that execute that kernel for a given kernel call is specified using a new <<<...>>> execution configuration syntax (see C++ Language Extensions). Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through built-in variables.
使用 __global__ 声明说明符定义内核,并使用新的 <<<...>>> 执行配置语法指定为给定内核调用执行该内核的 CUDA 线程数(请参阅 C++语言扩展)。每个执行内核的线程都会被赋予一个唯一的线程 ID ,该 ID 可以在内核中通过内置变量进行访问。
Thread Hierarachy: 线程层次结构
- grids - blocks - threads
- 块内线程驻留在同一个 core 上,共享内存
- blocks, threads 由三维下标索引
- threadIdx.x, .y, .z
- blockIdx.x, .y, .z
- block 尺寸:
- blockDim.x, .y, .z
For convenience, threadIdx is a 3-component vector, so that threads can be identified using a one-dimensional, two-dimensional, or three-dimensional thread index, forming a one-dimensional, two-dimensional, or three-dimensional block of threads, called a thread block. This provides a natural way to invoke computation across the elements in a domain such as a vector, matrix, or volume.
The index of a thread and its thread ID relate to each other in a straightforward way:
- For a one-dimensional block, they are the same;
- for a two-dimensional block of size
(Dx, Dy), the thread ID of a thread of index(x, y)is(x + y Dx); - for a three-dimensional block of size
(Dx, Dy, Dz), the thread ID of a thread of index(x, y, z)is(x + y Dx + z Dx Dy).
There is a limit to the number of threads per block, since all threads of a block are expected to reside on the same streaming multiprocessor core and must share the limited memory resources of that core. On current GPUs, a thread block may contain up to 1024 threads.
每个块的线程数量是有限的,因为块的所有线程都应该驻留在同一个流式多处理器核心上,并且必须共享该核心的有限内存资源。在当前的 GPU 上,一个线程块最多可以包含 1024 个线程。
However, a kernel can be executed by multiple equally-shaped thread blocks, so that the total number of threads is equal to the number of threads per block times the number of blocks.
然而,一个内核可以由多个形状相同的线程块来执行,因此线程总数等于每个块的线程数乘以块数。
Blocks are organized into a one-dimensional, two-dimensional, or three-dimensional grid of thread blocks as illustrated by Figure 4. The number of thread blocks in a grid is usually dictated by the size of the data being processed, which typically exceeds the number of processors in the system.
块被组织成一维、二维或三维线程块网格,如图 4 所示。网格中线程块的数量通常由正在处理的数据大小决定,该数据通常超过系统中处理器的数量。
Extending the previous MatAdd() example to handle multiple blocks, the code becomes as follows.
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N]) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses. More precisely, one can specify synchronization points in the kernel by calling the __syncthreads() intrinsic function;
__syncthreads() acts as a barrier at which all threads in the block must wait before any is allowed to proceed. In addition to __syncthreads(), the Cooperative Groups API provides a rich set of thread-synchronization primitives.
块内的线程可以通过某些共享内存共享数据并同步其执行来协调内存访问来进行协作。更准确地说,可以通过调用__syncthreads()内部函数来指定内核中的同步点;
__syncthreads()充当屏障,块中的所有线程都必须等待,然后才允许任何线程继续进行。除了__syncthreads()之外,协作组 API 还提供了一组丰富的线程同步原语。
For efficient cooperation, the shared memory is expected to be a low-latency memory near each processor core (much like an L1 cache) and __syncthreads() is expected to be lightweight.
为了高效合作,共享内存应该是每个处理器核心附近的低延迟内存(很像 L1 缓存),并且__syncthreads()应该是轻量级的。
Memory Hierarachy: 内存层次结构
CUDA threads may access data from multiple memory spaces during their execution as illustrated by Figure 6. Each thread has private local memory. Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block. Thread blocks in a thread block cluster can perform read, write, and atomics operations on each other’s shared memory. All threads have access to the same global memory.
CUDA 线程在执行期间可以访问多个内存空间中的数据,如图 6 所示。每个线程都有私有本地内存。每个线程块都有对该块的所有线程可见的共享内存,并且与该块具有相同的生命周期。线程块簇中的线程块可以对彼此的共享内存执行读、写和原子操作。所有线程都可以访问相同的全局内存。
There are also two additional read-only memory spaces accessible by all threads: the constant and texture memory spaces. The global, constant, and texture memory spaces are optimized for different memory usages (see Device Memory Accesses). Texture memory also offers different addressing modes, as well as data filtering, for some specific data formats (see Texture and Surface Memory).
还有两个可供所有线程访问的附加只读内存空间:常量内存空间和纹理内存空间。全局、常量和纹理内存空间针对不同的内存使用进行了优化(请参阅设备内存访问)。纹理内存还为某些特定的数据格式提供不同的寻址模式以及数据过滤(请参阅纹理和表面内存)。
The global, constant, and texture memory spaces are persistent across kernel launches by the same application.
全局、常量和纹理内存空间在同一应用程序的内核启动过程中是持久的。

Heteroheneous Programming: 异构编程
As illustrated by Figure 7, the CUDA programming model assumes that the CUDA threads execute on a physically separate device that operates as a coprocessor to the host running the C++ program. This is the case, for example, when the kernels execute on a GPU and the rest of the C++ program executes on a CPU. 如图 7 所示,CUDA 编程模型假设 CUDA 线程在物理上独立的设备上执行,该设备作为运行 C++ 程序的主机的协处理器运行。例如,当内核在 GPU 上执行而 C++ 程序的其余部分在 CPU 上执行时,就会出现这种情况。
The CUDA programming model also assumes that both the host and the device maintain their own separate memory spaces in DRAM, referred to as host memory and device memory, respectively. Therefore, a program manages the global, constant, and texture memory spaces visible to kernels through calls to the CUDA runtime (described in Programming Interface). This includes device memory allocation and deallocation as well as data transfer between host and device memory. CUDA 编程模型还假设主机和设备都在 DRAM 中维护自己独立的内存空间,分别称为主机内存和设备内存。因此,程序通过调用 CUDA 运行时(在编程接口中描述)来管理内核可见的全局、常量和纹理内存空间。这包括设备内存分配和释放以及主机和设备内存之间的数据传输。
Unified Memory provides managed memory to bridge the host and device memory spaces. Managed memory is accessible from all CPUs and GPUs in the system as a single, coherent memory image with a common address space. This capability enables oversubscription of device memory and can greatly simplify the task of porting applications by eliminating the need to explicitly mirror data on host and device. See Unified Memory Programming for an introduction to Unified Memory. 统一内存提供托管内存来桥接主机和设备内存空间。托管内存可作为具有公共地址空间的单个一致内存映像从系统中的所有 CPU 和 GPU 进行访问。此功能可实现设备内存的超额订阅,并且无需在主机和设备上显式镜像数据,从而大大简化移植应用程序的任务。有关统一内存的介绍,请参阅统一内存编程。
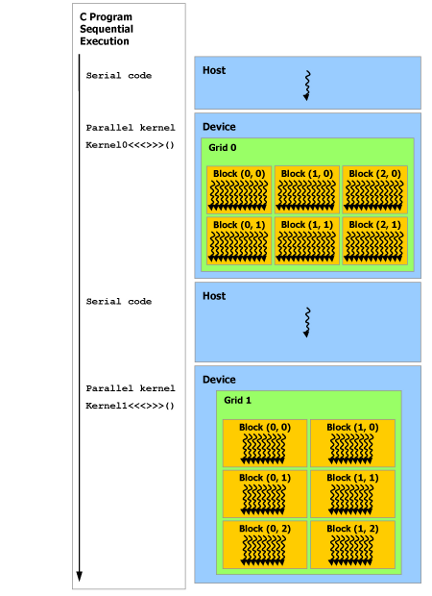
Serial code executes on the host while parallel code executes on the device. 串行代码在主机上执行,而并行代码在设备上执行。
Asynchronous SIMT Programming Model: 异步 SIMT 编程模型
In the CUDA programming model a thread is the lowest level of abstraction for doing a computation or a memory operation. Starting with devices based on the NVIDIA Ampere GPU architecture, the CUDA programming model provides acceleration to memory operations via the asynchronous programming model. The asynchronous programming model defines the behavior of asynchronous operations with respect to CUDA threads.
在 CUDA 编程模型中,线程是执行计算或内存操作的最低抽象级别。从基于 NVIDIA Ampere GPU 架构的设备开始,CUDA 编程模型通过异步编程模型提供内存操作加速。异步编程模型定义了与 CUDA 线程相关的异步操作的行为。
The asynchronous programming model defines the behavior of Asynchronous Barrier for synchronization between CUDA threads. The model also explains and defines how cuda::memcpy_async can be used to move data asynchronously from global memory while computing in the GPU.
异步编程模型定义了用于 CUDA 线程之间同步的异步屏障的行为。该模型还解释并定义了如何使用cuda::memcpy_async在 GPU 中计算时从全局内存异步移动数据。
2.5.1. Asynchronous Operations
2.5.1.异步操作
An asynchronous operation is defined as an operation that is initiated by a CUDA thread and is executed asynchronously as-if by another thread. In a well formed program one or more CUDA threads synchronize with the asynchronous operation. The CUDA thread that initiated the asynchronous operation is not required to be among the synchronizing threads. 异步操作被定义为由 CUDA 线程发起并像由另一个线程一样异步执行的操作。在格式良好的程序中,一个或多个 CUDA 线程与异步操作同步。启动异步操作的 CUDA 线程不需要位于同步线程中。
Such an asynchronous thread (an as-if thread) is always associated with the CUDA thread that initiated the asynchronous operation. An asynchronous operation uses a synchronization object to synchronize the completion of the operation. Such a synchronization object can be explicitly managed by a user (e.g., cuda::memcpy_async) or implicitly managed within a library (e.g., cooperative_groups::memcpy_async). 这样的异步线程(as-if 线程)始终与启动异步操作的 CUDA 线程相关联。异步操作使用同步对象来同步操作的完成。这样的同步对象可以由用户显式管理(例如, cuda::memcpy_async )或在库中隐式管理(例如, cooperative_groups::memcpy_async )。
A synchronization object could be a cuda::barrier or a cuda::pipeline. These objects are explained in detail in Asynchronous Barrier and Asynchronous Data Copies using cuda::pipeline. These synchronization objects can be used at different thread scopes. A scope defines the set of threads that may use the synchronization object to synchronize with the asynchronous operation. The following table defines the thread scopes available in CUDA C++ and the threads that can be synchronized with each. 同步对象可以是cuda::barrier或cuda::pipeline 。这些对象在使用 cuda::pipeline 的异步屏障和异步数据副本中详细解释。这些同步对象可以在不同的线程范围内使用。范围定义了可以使用同步对象来与异步操作同步的线程集。下表定义了 CUDA C++ 中可用的线程范围以及可以与每个线程同步的线程。
Compute Capability: 计算能力
Programming Interface 编程接口
Hardware Implementation 硬件实现
Performance Guidelines 性能指南
PTX Parallel Thread Execution
PTX: a low-level parallel thread execution virtual machine and instruction set architecture.
PTX 是一种低级并行线程执行虚拟机和指令集体系结构。
PTX exposes the GPU as data-parallel computing device.
Numba
Overview 概述
Numba supports CUDA GPU programming by directly compiling a restricted subset of Python code into CUDA kernels and device functions following the CUDA execution model. Kernels written in Numba appear to have direct access to NumPy arrays. NumPy arrays are transferred between the CPU and the GPU automatically.
Numba 通过将 Python 代码的受限子集直接编译为遵循 CUDA 执行模型的 CUDA 内核和设备函数来支持 CUDA GPU 编程。用 Numba 编写的内核似乎可以直接访问 NumPy 数组。 NumPy 数组在 CPU 和 GPU 之间自动传输。
Install CUDA
NVIDIA CUDA Installation Guide for Linux
Other Resources
Programming Massively Parallel Processors: A Hands-on Approach
Programming Massively Parallel Processors: A Hands-on Approach, Second Edition, teaches students how to program massively parallel processors. It offers a detailed discussion of various techniques for constructing parallel programs. Case studies are used to demonstrate the development process, which begins with computational thinking and ends with effective and efficient parallel programs. This guide shows both student and professional alike the basic concepts of parallel programming and GPU architecture. Topics of performance, floating-point format, parallel patterns, and dynamic parallelism are covered in depth. This revised edition contains more parallel programming examples, commonly-used libraries such as Thrust, and explanations of the latest tools. It also provides new coverage of CUDA 5.0, improved performance, enhanced development tools, increased hardware support, and more; increased coverage of related technology, OpenCL and new material on algorithm patterns, GPU clusters, host programming, and data parallelism; and two new case studies (on MRI reconstruction and molecular visualization) that explore the latest applications of CUDA and GPUs for scientific research and high-performance computing. This book should be a valuable resource for advanced students, software engineers, programmers, and hardware engineers.
Programming Massively Parallel Processors: A Hands-on Approach,第二版,教授学生如何对大规模并行处理器进行编程。它详细讨论了用于构建并行程序的各种技术。案例研究用于演示开发过程,该过程从计算思维开始,以有效和高效的并行程序结束。本指南向学生和专业人士展示了并行编程和 GPU 架构的基本概念。深入介绍了性能、浮点格式、并行模式和动态并行性等主题。此修订版包含更多并行编程示例、常用库(如 Thrust)以及最新工具的解释。它还提供了 CUDA 5.0 的新覆盖范围、改进的性能、增强的开发工具、增强的硬件支持等;增加了相关技术、OpenCL 和有关算法模式、GPU 集群、主机编程和数据并行性的新材料的覆盖范围;以及两个新的案例研究(关于 MRI 重建和分子可视化),探索 CUDA 和 GPU 在科学研究和高性能计算中的最新应用。这本书应该是高级学生、软件工程师、程序员和硬件工程师的宝贵资源。
CUDA Examples
#include <cuda_runtime.h>
#include <iostream>
// CUDA kernel function for vector addition
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x; // Calculate global thread index
if (i < N) {
C[i] = A[i] + B[i];
}
}
int main() {
int N = 1024;
size_t size = N * sizeof(float);
// Allocate host memory
float *h_A = (float*)malloc(size);
float *h_B = (float*)malloc(size);
float *h_C = (float*)malloc(size);
// Initialize vectors
for (int i = 0; i < N; i++) {
h_A[i] = static_cast<float>(i);
h_B[i] = static_cast<float>(i * 2);
}
// Allocate device memory
float *d_A, *d_B, *d_C;
cudaMalloc((void**)&d_A, size);
cudaMalloc((void**)&d_B, size);
cudaMalloc((void**)&d_C, size);
// Copy data from host to device
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Launch kernel
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Copy result back to host
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Print some results
for (int i = 0; i < 10; i++) {
std::cout << h_C[i] << std::endl;
}
// Free memory
free(h_A); free(h_B); free(h_C);
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
return 0;
}